块设备子系统架构 在Linux中,我们通常使用磁盘文件系统EXT4、UBIFS等访问磁盘,但是磁盘也有一种原始设备的访问方式,如直接访问/dev/sdb1等,所有的EXT4、UBIFS、原始块设备都工作与VFS之下,在它们之下又包含块I/O调度层以进行排序和合并操作。Linux的块设备子系统如下所示。
块设备驱动结构 block_device_operations结构体 在块设备驱动中,它是对块设备操作的集合,定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 struct block_device_operations { int (*open) (struct block_device *, fmode_t); void (*release) (struct gendisk *, fmode_t); int (*rw_page)(struct block_device *, sector_t, struct page *, unsigned int); int (*ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); int (*compat_ioctl) (struct block_device *, fmode_t, unsigned, unsigned long); unsigned int (*check_events) (struct gendisk *disk, unsigned int clearing); /* ->media_changed() is DEPRECATED, use ->check_events() instead */ int (*media_changed) (struct gendisk *); void (*unlock_native_capacity) (struct gendisk *); int (*revalidate_disk) (struct gendisk *); int (*getgeo)(struct block_device *, struct hd_geometry *); /* this callback is with swap_lock and sometimes page table lock held */ void (*swap_slot_free_notify) (struct block_device *, unsigned long); int (*report_zones)(struct gendisk *, sector_t sector, unsigned int nr_zones, report_zones_cb cb, void *data); struct module *owner; const struct pr_ops *pr_ops; };
gendisk结构体 在内核中,使用gendisk(通用磁盘)结构体来表示一个独立的磁盘设备,这个结构体定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 struct gendisk { /* major, first_minor and minors are input parameters only, * don't use directly. Use disk_devt() and disk_max_parts(). */ int major; /* major number of driver */ int first_minor; int minors; /* maximum number of minors, =1 for * disks that can't be partitioned. */ char disk_name[DISK_NAME_LEN]; /* name of major driver */ char *(*devnode)(struct gendisk *gd, umode_t *mode); unsigned short events; /* supported events */ unsigned short event_flags; /* flags related to event processing */ /* Array of pointers to partitions indexed by partno. * Protected with matching bdev lock but stat and other * non-critical accesses use RCU. Always access through * helpers. */ struct disk_part_tbl __rcu *part_tbl; struct hd_struct part0; const struct block_device_operations *fops; struct request_queue *queue; void *private_data; int flags; struct rw_semaphore lookup_sem; struct kobject *slave_dir; struct timer_rand_state *random; atomic_t sync_io; /* RAID */ struct disk_events *ev; #ifdef CONFIG_BLK_DEV_INTEGRITY struct kobject integrity_kobj; #endif /* CONFIG_BLK_DEV_INTEGRITY */ int node_id; struct badblocks *bb; struct lockdep_map lockdep_map; };
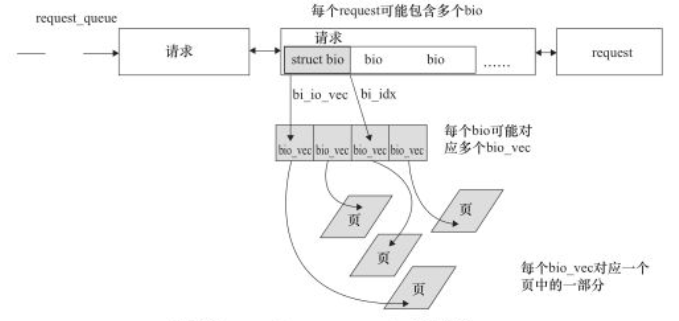
bio、request和request_queue 通常一个bio对应上层传递给块层的I/O请求。每个bio结构体实例及其包含的bvec_iter、bio_vec结构体实例描述了该I/O请求的开始扇区、数据方向、数据放入的页,其定义如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 struct bio { struct bio *bi_next; /* request queue link */ struct gendisk *bi_disk; unsigned int bi_opf; /* bottom bits req flags, * top bits REQ_OP. Use * accessors. */ unsigned short bi_flags; /* status, etc and bvec pool number */ unsigned short bi_ioprio; unsigned short bi_write_hint; blk_status_t bi_status; u8 bi_partno; atomic_t __bi_remaining; struct bvec_iter bi_iter; bio_end_io_t *bi_end_io; void *bi_private; #ifdef CONFIG_BLK_CGROUP /* * Represents the association of the css and request_queue for the bio. * If a bio goes direct to device, it will not have a blkg as it will * not have a request_queue associated with it. The reference is put * on release of the bio. */ struct blkcg_gq *bi_blkg; struct bio_issue bi_issue; #ifdef CONFIG_BLK_CGROUP_IOCOST u64 bi_iocost_cost; #endif #endif union { #if defined(CONFIG_BLK_DEV_INTEGRITY) struct bio_integrity_payload *bi_integrity; /* data integrity */ #endif }; unsigned short bi_vcnt; /* how many bio_vec's */ /* * Everything starting with bi_max_vecs will be preserved by bio_reset() */ unsigned short bi_max_vecs; /* max bvl_vecs we can hold */ atomic_t __bi_cnt; /* pin count */ struct bio_vec *bi_io_vec; /* the actual vec list */ struct bio_set *bi_pool; /* * We can inline a number of vecs at the end of the bio, to avoid * double allocations for a small number of bio_vecs. This member * MUST obviously be kept at the very end of the bio. */ struct bio_vec bi_inline_vecs[0]; };
与bio对应的数据每次存放的内存不一定是连续的,bio_vec结构体就是用来描述与这个bio请求对应的所有的内存,它可能不总是一个页面里面,因此需要一个向量。在向量中,每个元素实际是一个[page,offset,len],一般称为一个片段。
I/O调度算法可将连续的bio合并成一个请求。请求是bio经由I/O调度进行调整后的结果,这是请求和bio的区别。因此,一个request可以包含多个bio。当bio被提交给I/O调度器是,I/O调度器可能会将这个bio插入现存的请求中,也可能生成新的请求。
每个块设备或则块设备的分区都对应又自身的request_queue,从I/O调度器合并和排序出来的请求会被分发到设备级的request_queue。其中请求队列、request、bio和bio_vec之间的关系如下图所示。
关于request_queue的相关操作接口定义在linux/blkdev.h中。
块设备驱动的实现 初始化 在块设备的注册和初始化阶段,块设备驱动首先需要将它们自己注册到内核,其相关的接口如下:
1 2 extern int register_blkdev(unsigned int, const char *); extern void unregister_blkdev(unsigned int, const char *);
除此之外,在块设备驱动初始化过程中,通常需要完成分配、初始化请求队列,绑定请求队列和请求处理函数的工作,并且可能会分配、初始化gendisk.
打开与释放 块设备驱动的open()函数和其字符设备驱动的对等体不太相似,前者不以相关的inode和file结构体指针作为参数。在open()中,我们可以通过block_device参数bdev获取private_data;在release()中,则通过gendisk参数disk获取。如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 static int xxx_open(struct block_device *bdev, fmode_t mode) { struct xxx_dev *xxx_dev = bdev->bd_disk->private_data; ... return 0; } static void xxx_release(struct gendisk *disk, fmode_t mode) { struct xxx_device *dev = disk->private_data; ... }
ioctl函数 与字符设备驱动一样,块设备可以包含一个ioctl()函数以提供对设备的I/O控制能力。实际上,高层的块设备层代码处理了绝大多数I/O控制,如BLKFLUSBUF、BLKROSET、BLKDSCARD等。因此,在具体的块设备驱动中通常只需要实现与设备相关的特定ioctl命令。
I/O请求处理 使用请求队列 示例来源于drivers/memstick/core/ms_block.c,如下展示了块设备驱动请求函数例程:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 static blk_status_t msb_queue_rq(struct blk_mq_hw_ctx *hctx, const struct blk_mq_queue_data *bd) { struct memstick_dev *card = hctx->queue->queuedata; struct msb_data *msb = memstick_get_drvdata(card); struct request *req = bd->rq; dbg_verbose("Submit request"); spin_lock_irq(&msb->q_lock); if (msb->card_dead) { dbg("Refusing requests on removed card"); WARN_ON(!msb->io_queue_stopped); spin_unlock_irq(&msb->q_lock); blk_mq_start_request(req); return BLK_STS_IOERR; } if (msb->req) { spin_unlock_irq(&msb->q_lock); return BLK_STS_DEV_RESOURCE; } blk_mq_start_request(req); msb->req = req; if (!msb->io_queue_stopped) queue_work(msb->io_queue, &msb->io_work); spin_unlock_irq(&msb->q_lock); return BLK_STS_OK; }
正常情况下,通过queue_work启动工作队列之下msb_io_work这个函数,它的原型如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 static void msb_io_work(struct work_struct *work) { struct msb_data *msb = container_of(work, struct msb_data, io_work); int page, error, len; sector_t lba; struct scatterlist *sg = msb->prealloc_sg; struct request *req; dbg_verbose("IO: work started"); while (1) { spin_lock_irq(&msb->q_lock); if (msb->need_flush_cache) { msb->need_flush_cache = false; spin_unlock_irq(&msb->q_lock); msb_cache_flush(msb); continue; } req = msb->req; if (!req) { dbg_verbose("IO: no more requests exiting"); spin_unlock_irq(&msb->q_lock); return; } spin_unlock_irq(&msb->q_lock); /* process the request */ dbg_verbose("IO: processing new request"); blk_rq_map_sg(msb->queue, req, sg); lba = blk_rq_pos(req); sector_div(lba, msb->page_size / 512); page = sector_div(lba, msb->pages_in_block); if (rq_data_dir(msb->req) == READ) error = msb_do_read_request(msb, lba, page, sg, blk_rq_bytes(req), &len); else error = msb_do_write_request(msb, lba, page, sg, blk_rq_bytes(req), &len); if (len && !blk_update_request(req, BLK_STS_OK, len)) { __blk_mq_end_request(req, BLK_STS_OK); spin_lock_irq(&msb->q_lock); msb->req = NULL; spin_unlock_irq(&msb->q_lock); } if (error && msb->req) { blk_status_t ret = errno_to_blk_status(error); dbg_verbose("IO: ending one sector of the request with error"); blk_mq_end_request(req, ret); spin_lock_irq(&msb->q_lock); msb->req = NULL; spin_unlock_irq(&msb->q_lock); } if (msb->req) dbg_verbose("IO: request still pending"); } }
在读写无错的情况下,调用__blk_mq_end_request(req, BLK_STS_OK)实际上告诉了上层该请求处理完成。如果读写有错,则调用blk_mq_end_request(req, ret)把出错原因作为第2个参数传入上层。
如上代码中blk_rq_map_sg()实现于block/blk-merge.c中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 int blk_rq_map_sg(struct request_queue *q, struct request *rq, struct scatterlist *sglist) { struct scatterlist *sg = NULL; int nsegs = 0; if (rq->rq_flags & RQF_SPECIAL_PAYLOAD) nsegs = __blk_bvec_map_sg(rq->special_vec, sglist, &sg); else if (rq->bio && bio_op(rq->bio) == REQ_OP_WRITE_SAME) nsegs = __blk_bvec_map_sg(bio_iovec(rq->bio), sglist, &sg); else if (rq->bio) nsegs = __blk_bios_map_sg(q, rq->bio, sglist, &sg); ... return nsegs; } static inline int __blk_bvec_map_sg(struct bio_vec bv, struct scatterlist *sglist, struct scatterlist **sg) { *sg = blk_next_sg(sg, sglist); sg_set_page(*sg, bv.bv_page, bv.bv_len, bv.bv_offset); return 1; } static int __blk_bios_map_sg(struct request_queue *q, struct bio *bio, struct scatterlist *sglist, struct scatterlist **sg) { struct bio_vec uninitialized_var(bvec), bvprv = { NULL }; struct bvec_iter iter; int nsegs = 0; bool new_bio = false; for_each_bio(bio) { bio_for_each_bvec(bvec, bio, iter) { /* * Only try to merge bvecs from two bios given we * have done bio internal merge when adding pages * to bio */ if (new_bio && __blk_segment_map_sg_merge(q, &bvec, &bvprv, sg)) goto next_bvec; if (bvec.bv_offset + bvec.bv_len <= PAGE_SIZE) nsegs += __blk_bvec_map_sg(bvec, sglist, sg); else nsegs += blk_bvec_map_sg(q, &bvec, sglist, sg); next_bvec: new_bio = false; } if (likely(bio->bi_iter.bi_size)) { bvprv = bvec; new_bio = true; } } return nsegs; }
blk_rq_map_sg()由如上实现我们可知其功能是遍历所有的bio,以及所有的片段,将所有于某请求相关的页组成一个scatter/gather的列表。
不使用请求队列 使用请求队列对于一个机械磁盘设备而言的确有助于提高系统的性能,但是对于RAMDISK、ZRAM等完全可真正随机访问的设备而言,无法从高级的请求队列逻辑中获益。对于这些设备,块层支持“无队列”模式,为使用这个模式,驱动必须提供一个“制造请求”的函数,而不是一个请求处理函数。对于这类设备的I/O请求实现可参考如下代码(drivers/block/zram/zram_drv.c)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 static void __zram_make_request(struct zram *zram, struct bio *bio) { int offset; u32 index; struct bio_vec bvec; struct bvec_iter iter; index = bio->bi_iter.bi_sector >> SECTORS_PER_PAGE_SHIFT; offset = (bio->bi_iter.bi_sector & (SECTORS_PER_PAGE - 1)) << SECTOR_SHIFT; switch (bio_op(bio)) { case REQ_OP_DISCARD: case REQ_OP_WRITE_ZEROES: zram_bio_discard(zram, index, offset, bio); bio_endio(bio); return; default: break; } bio_for_each_segment(bvec, bio, iter) { struct bio_vec bv = bvec; unsigned int unwritten = bvec.bv_len; do { bv.bv_len = min_t(unsigned int, PAGE_SIZE - offset, unwritten); if (zram_bvec_rw(zram, &bv, index, offset, bio_op(bio), bio) < 0) goto out; bv.bv_offset += bv.bv_len; unwritten -= bv.bv_len; update_position(&index, &offset, &bv); } while (unwritten); } bio_endio(bio); return; out: bio_io_error(bio); } /* * Handler function for all zram I/O requests. */ static blk_qc_t zram_make_request(struct request_queue *queue, struct bio *bio) { struct zram *zram = queue->queuedata; if (!valid_io_request(zram, bio->bi_iter.bi_sector, bio->bi_iter.bi_size)) { atomic64_inc(&zram->stats.invalid_io); goto error; } __zram_make_request(zram, bio); return BLK_QC_T_NONE; error: bio_io_error(bio); return BLK_QC_T_NONE; }
转载请注明来源,欢迎对文章中的引用来源进行考证,欢迎指出任何有错误或不够清晰的表达。可以在下面评论区评论,也可以邮件至 yxhlfx@163.com